
データマネジメント導入支援サービスには、次の3つがあります。
- データアーキテクチャ設計ワークショップ
- データマネジメント導入コンサルティングサービス
- データマネジメント運用請負サービス
データアーキテクチャ設計ワークショップ
企業のデータアキテクチャ(データの基本構造)を、次のようなワークショップ形式で設計していただくことで
- 企業全体の既存データには何がありどのような関係になっているのかを体系的に把握する
- ビジネスで付加価値を創出するために必要なデータを戦略的に収集する
ことができます。
- 形式
レクチャー+グループワークのワークショップ形式です。
ワークショップを通して実際の成果物を作成することで、お客様の知的資産を自身で作成する力を実践的に習得することができます。 - 時間
1ワークショップ
2時間です。 - 参加人数
1ワークショップ
3名から5名が目安です。 - 成果物
世界標準のモデル記述言語UMLを使って、お客様のビジネス、データ、システムのモデル(設計図)を作成します。
成果物はお客様のナレッジ(知的資産)になります。 - 場所
オンライン、または、お客様の指定場所で実施いたします。 - ご費用
ワークショップ単価/人×人数×回数で初回のご費用をお見積りします。
データマネジメント導入コンサルティングサービス
データマネジメント導入支援サービスの内容に従って、ワークショップを実施することで、企業にデータマネジメントを導入するサービスです。
データマネジメント運用請負サービス
データマネジメントを導入後、貴社のデータ管理者としてデータマネジメントの運用を遂行するサービスです。
ご興味がある方は、問い合わせフォームからご連絡ください。
データマネジメントの重要性
変化が激しく、不透明で先行きが予測できない昨今の経営環境を、
- Volatility(変動性)
- Uncertainty(不確実性)
- Complexity(複雑性)
- Ambiguity(不透明性)
の頭文字をとってVUCA(ブーカ)という言葉で表すことがあります。
それは、SNSやモバイル技術によって人と人がつながる時間や距離が短くなったことで、個人の欲望や考えが、複雑なネットワークを介してすぐに世界中に広がり、いつどこで、どんな需要が生まれるか読みづらく、欲求の新陳代謝も激しくなっているからではないでしょうか。
このように、先行き不透明で予測困難な時代、経験や勘に頼るのではなく
稼ぐ力を持つ資産としてのデータをどう利活用してくか
ということが会社を発展させていくための重要な課題となっています。
「データは新しい石油(Data is the new oil)」と言われています。
会社に眠っているデータを、人やAIが、いかにうまく利活用して企業価値を生み出すことができるかが重要なのです。
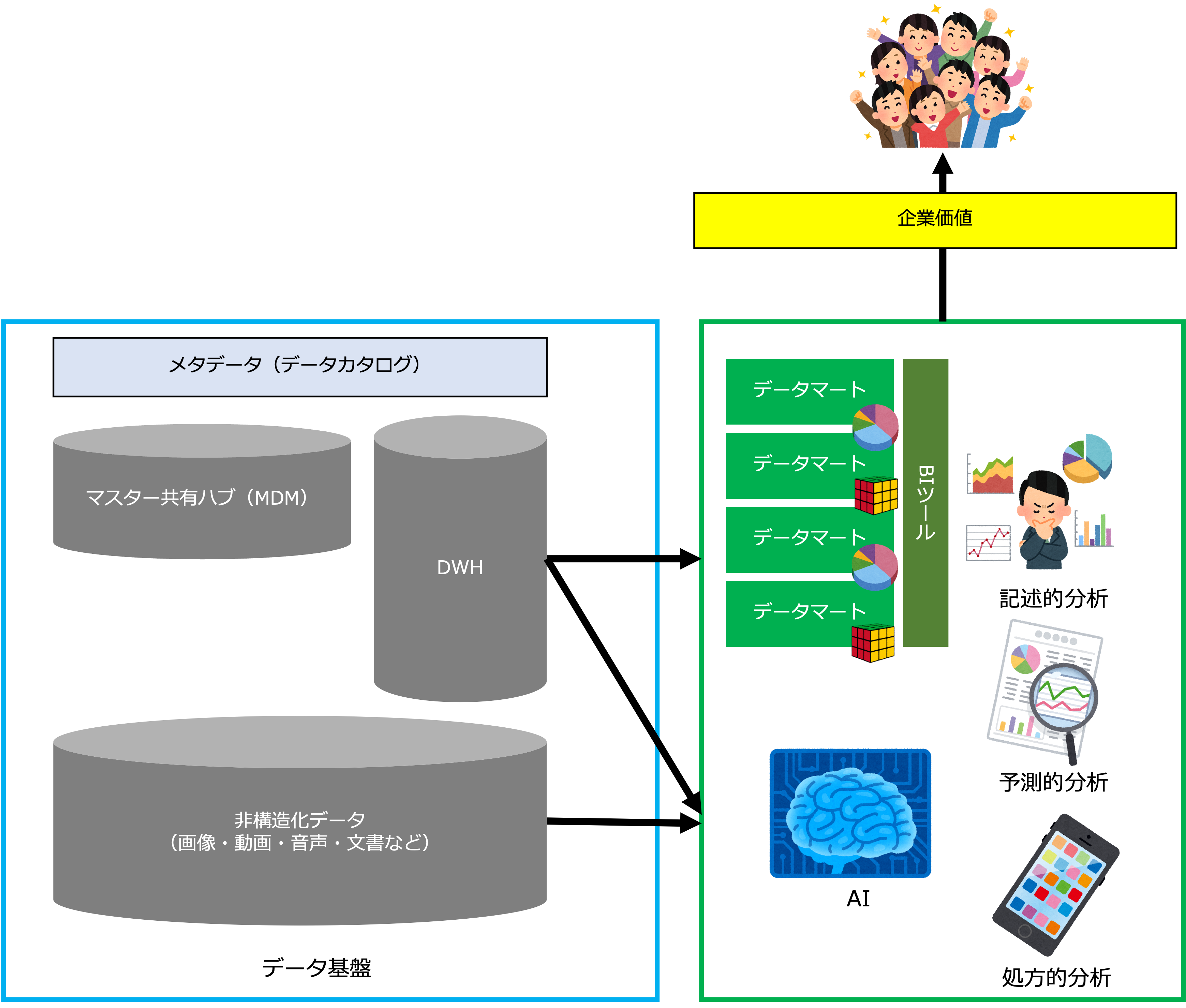
皆さんは、データドリブン経営という言葉をご存知でしょうか。
一般的には、経営判断やビジネス戦略の決定に、データや分析結果を活用することを指しますが、ここでは、企業をDXの一環と捉えて、
社員一人ひとりがデータを利活用して自律的に業務課題を解決することができる状態に変革すること
を目指します。
データドリブン経営は、データマネジメントが導入された後、マネジメントサイクルの戦略期間の運用フェーズで、データを利活用してマネジメントサイクル(PDCA)を遂行します。
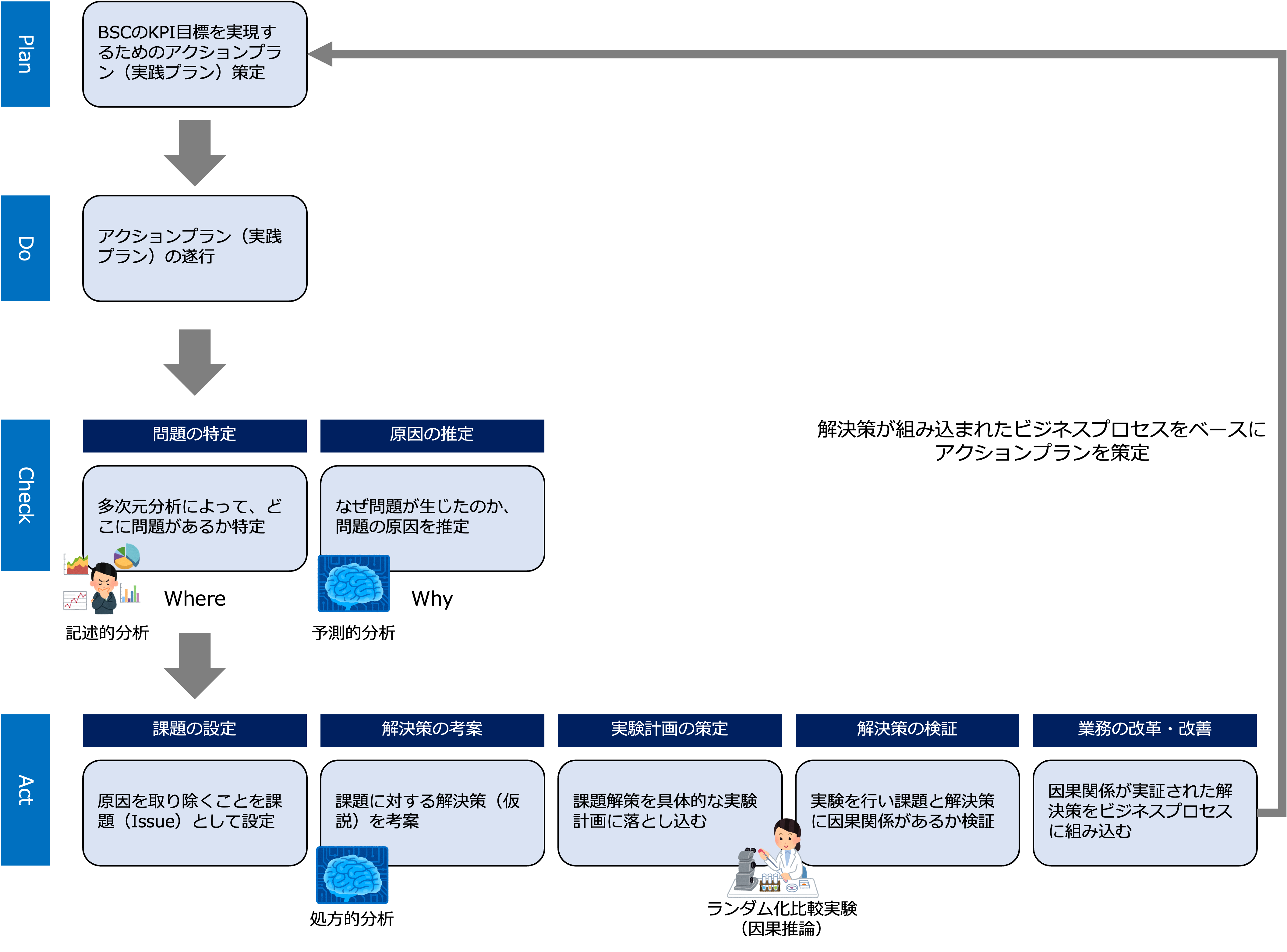
- 計画(Plan)
BSCのKPI目標を実現するためのアクションプラン(実践プラン)を策定します。 - 実行(Do)
アクションプラン(実践プラン)を遂行します。 - 検証(Check)
検証は次の順で行います。問題の特定(Where)
まず、KPI目標値と実績のGapである問題を発見します。
※KPI目標値には、ERMのフレームワークに従って、リスク許容度とリスクの発生可能性と影響度が設定されています。
次に、ドリルダウン・アップやスライシングによる多次元分析によって、どこに問題があるか特定します。
データ分析は、記述的分析、予測的分析、処方的分析に分けることができますが、多次元分析は、記述的分析(Descriptive Analytics)になります。
原因の推定(Why)
多次元分析によって、どこに(Where)問題があるか特定できたら、次に、なぜ(Why)問題が生じたのか、仮説推論(Abduction)で問題の原因を推定します。
そして、回帰分析など機械学習を通して原因の確からしさを検証します。
回帰分析は主に帰納(Induction)的な手法であり、与えられたデータから一般的な法則になる変数間の関係性を導きます。
なお、回帰分析は、予測的分析(Predictive Analytics)になります。 - 改善(Act)
改善は次の順で行います。課題の設定
まず、原因を取り除くことを課題(Issue)として設定します。
解決策の考案
次に、仮説推論(Abduction)で、課題に対する解決策(仮説)を考えます。
AIを活用した解決策(レコメンド、最適な治療法の提案、最適な学習経路の提案など)も含みます。
AIを活用した解決策は、処方的分析(Prescriptive Analytics)になります。
実験計画の策定
次に考案された課題解策を、ランダム化比較実験など因果推論の具体的な実験プランに落とし込みます。
解決策の検証
ランダム化比較実験を行い課題と解決策に、因果関係(一般的法則)があるか検証します。
すべての解決策(仮説)に統計的な有意性がない場合、課題(課題)も見直します。
業務の改革・改善
因果関係が実証された解決策をビジネスプロセスに組み込みます(実験から実践へ)。
ここでは、例えば、これまで人が行っていた活動をAIに置き換えたり、業務の流れそのものを変えるなど大幅なビジネスプロセスの変更を伴うものを業務改革と位置づけ、ある活動のビジネスルールの変更など、従来のビジネスプロセスの大幅な変更を伴わないものを業務改善と位置づけます。
そして、解決策が組み込まれたビジネスプロセスをベースにPlan(アクションプラン)を策定します。
実証された解決策を適用してアクションを実行し結論を導くのは演繹(Deduction)的アプローチです。
以上のように、データドリブン経営は、仮説検証を繰り返す科学的アプローチです。
PDCAの結果をすべて記録しノウハウとして蓄積することで学習し進化する組織が実現します。
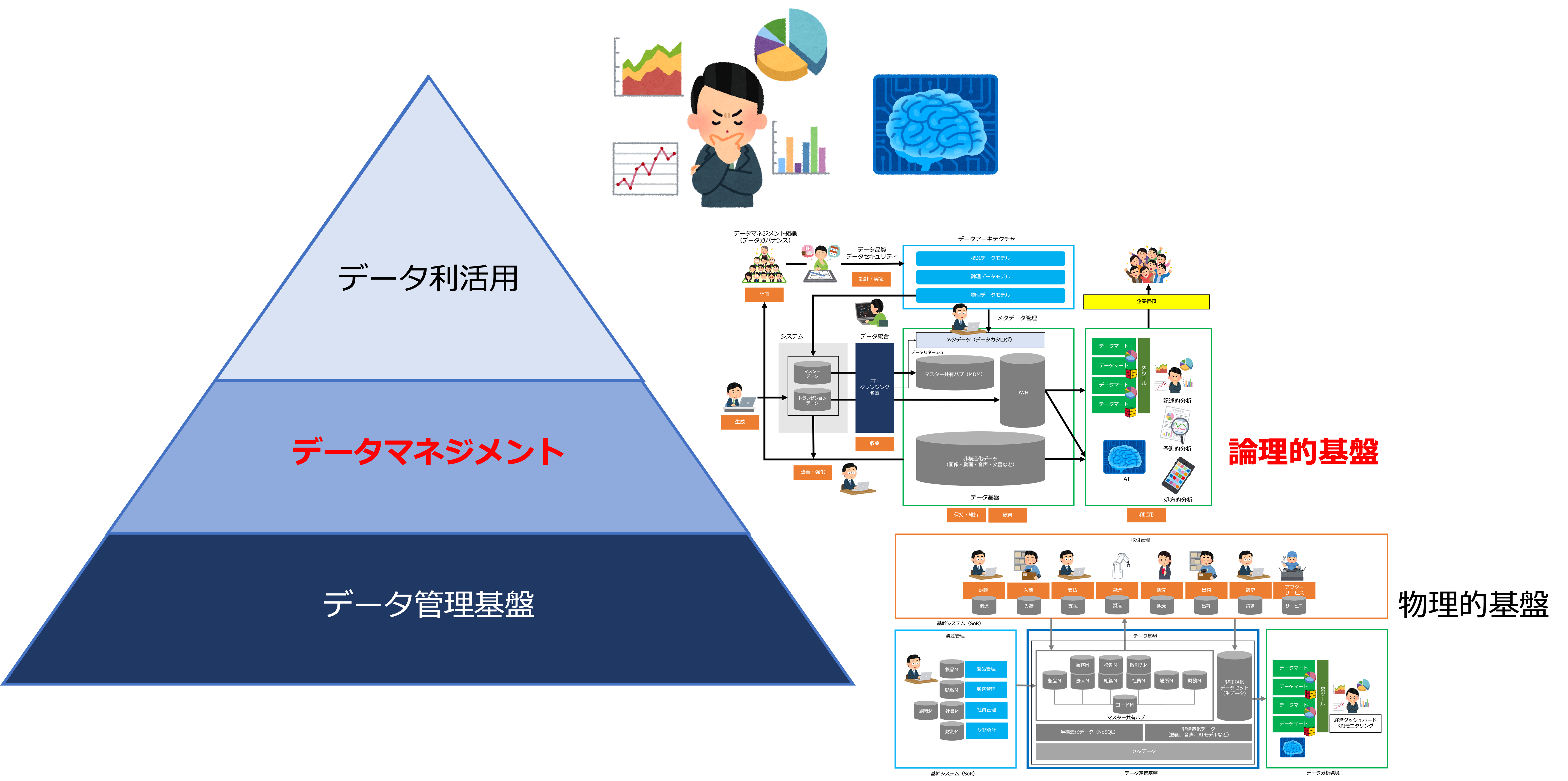
さて、データにはライフサイクルがあります。
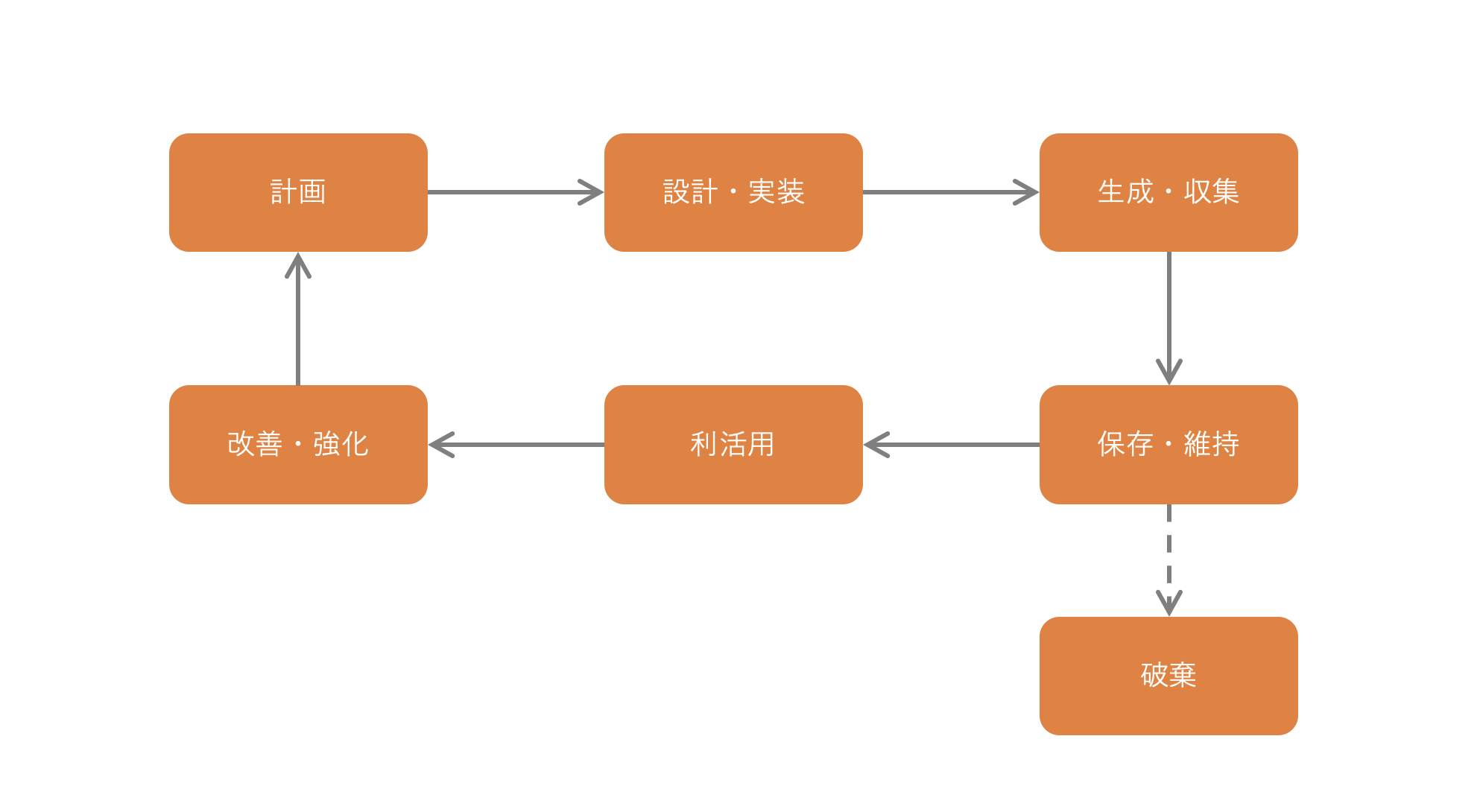
このデータのライフサイクルの中で、データが直接経済価値を生む活動は「データ利活用」です。
しかし、事業戦略を実現するために必要なデータを特定し、それを、どう収集し、どう活用するか考える計画活動がなければ、会社にとって必要なデータを計画的に収集し活用することはできません。
また、会社全体のデータを設計、実装し、生成、収集しなければ、適切な人が、適切なタイミングで、適切なデータを、適切な形式かつ適切な詳細度で活用することはできません。
間違ったデータの活用は、間違った意思決定につながりますし、誰もが機密データにアクセスできるようであればデータの漏洩リスクが高くなります。
さらに、データを適切に保存、維持しなければ、重要なデータが喪失する可能性もあります。
データを利活用するためには、データのライフサイクルを全体を通して、データを適切に管理するデータマネジメントが必要なのです。
データマネジメントに関する知識を体系立ててまとめた書籍にデータマネジメント知識体系(DMBOK)があります。
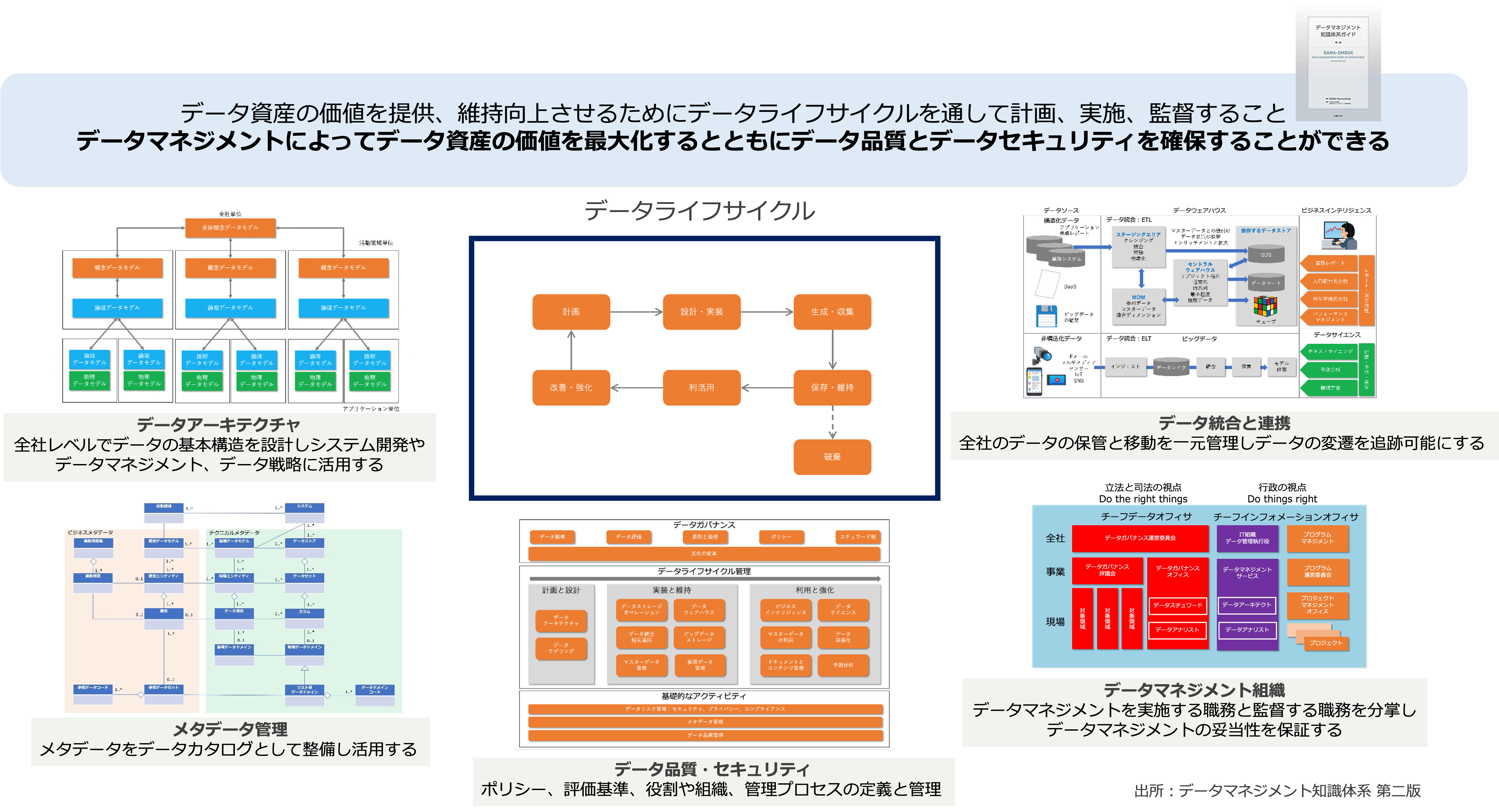
DMBOKでは、セキュリティや品質が確保されていないデータがもたらす事象として以下の例をあげています。
- 誤請求
- 顧客サービスコールの増加とそれを解決する能力の低下
- 事業機会の逸失による収益損失
- 合弁・買収の間に発生する業務統合の遅延
- 不正行為発覚の増加
- 不正なデータに起因する業務上の意思決定不備がもたらす損失
- 良好な信用力の欠如による事業の損失
データを効果的、効率的に利活用するためには、データを保護し、その品質を確保してデータの資産価値を維持向上させるためのデータマネジメントがとても重要です。
よく見受けられるのが、高額なデータウェアハウスを導入して、「後は、業務部門が自由に使ってください」、というアプローチです。
いくら箱(物理的基盤)だけ用意しても、
そこで、どんなデータを管理するのか、
メンテナンスはどうするのか、
ほしいデータの有無や所在、利用する際の制約に関する知識は誰が提供するのか、
など、データマネジメント(論理的基盤)が整備されていないと、業務部門も困惑するだけで、どうデータ利活用すればよいかわからず、宝の持ち腐れになってしまうのです。
なお、データマネジメントの詳細については、
【DMBOKで学ぶ】データマネジメントの導入方法
を御覧ください。
データマネジメント導入支援サービスの内容
ここでは、データマネジメント導入コンサルティングサービスの具体的な内容について説明します。
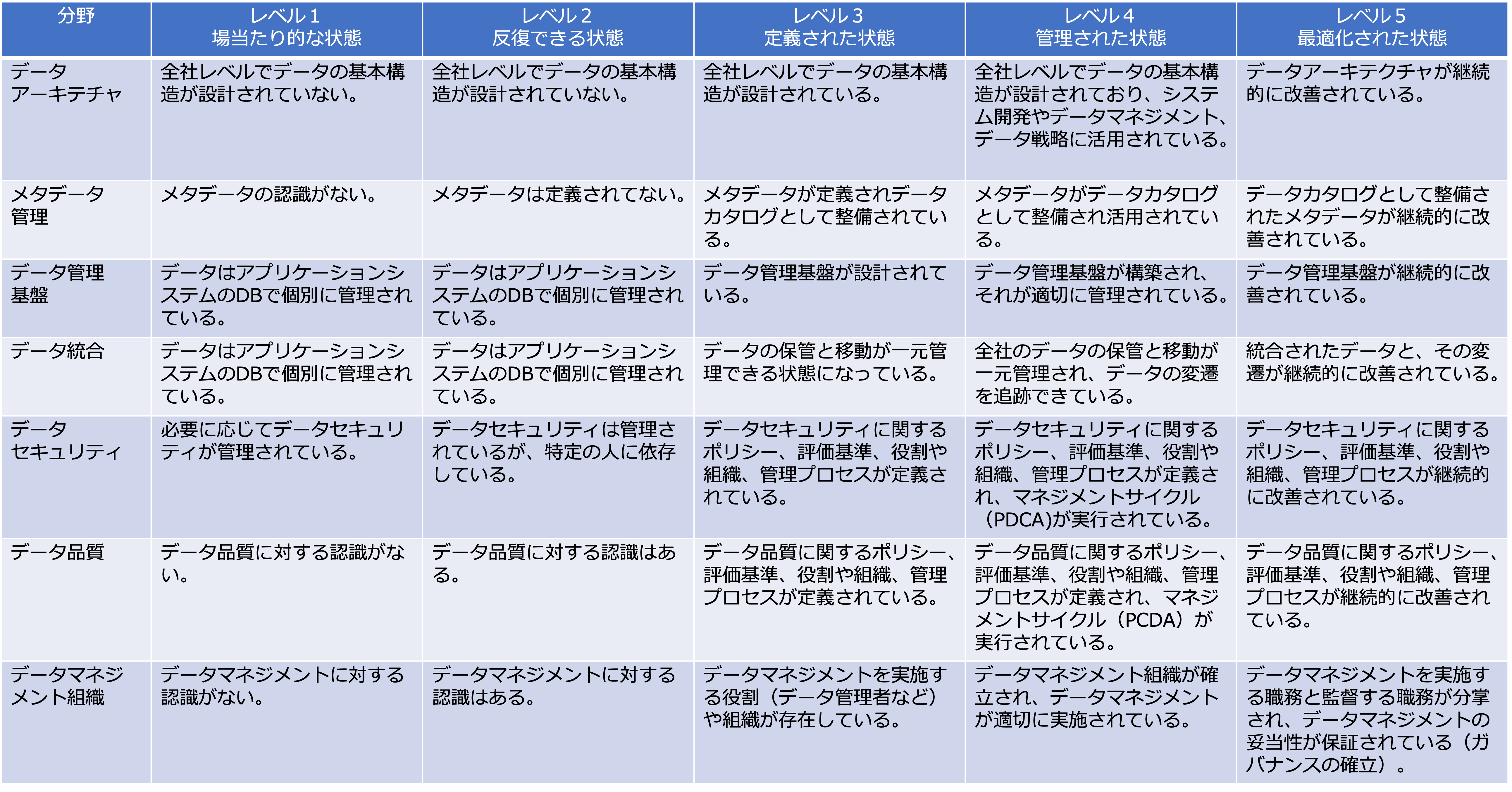
次の図は、DMBOKのデータマネジメント成熟度モデルを、各分野別に詳細化したものです。
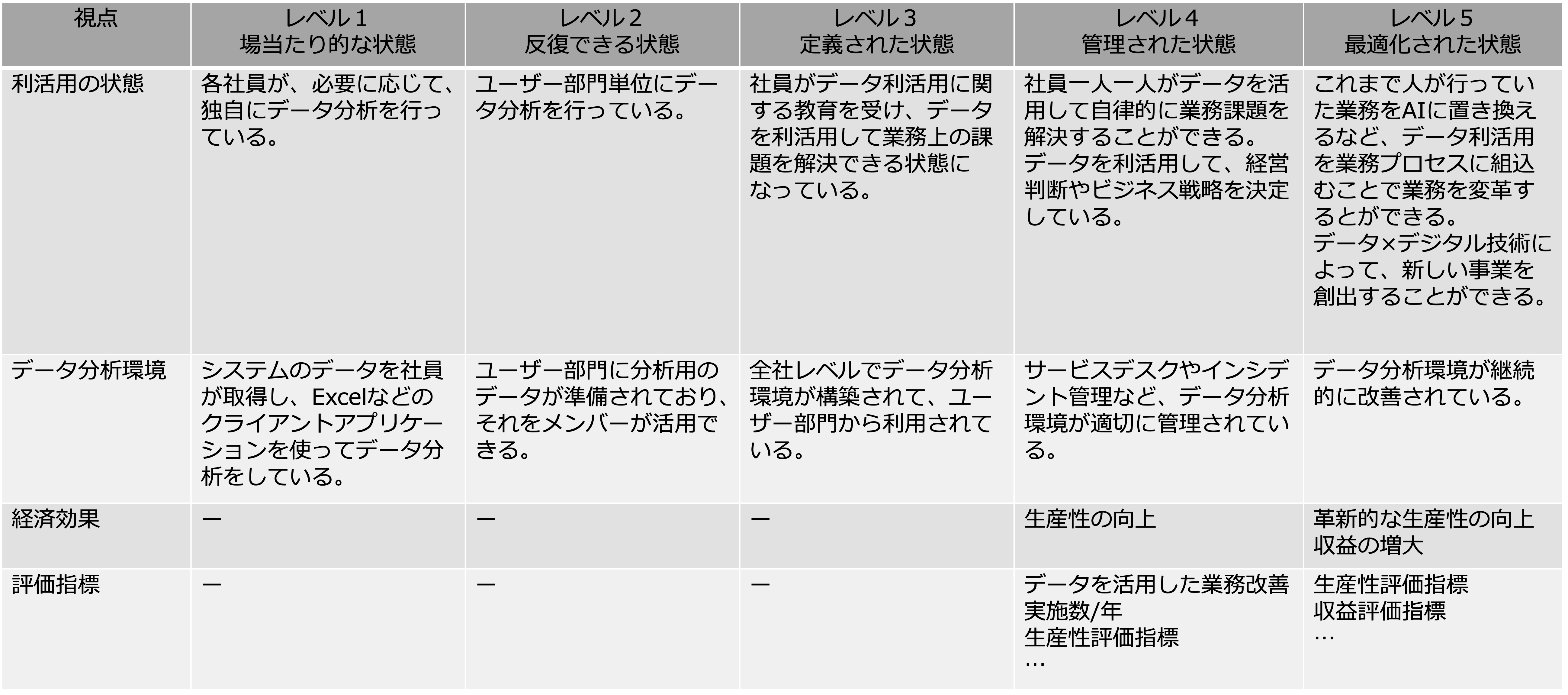
データマネジメント成熟度モデルに合わせて、次の図のように、データ利活用の成熟度も上がり、DXが進みます。
次の図は、データマネジメントの導入プロセスです。
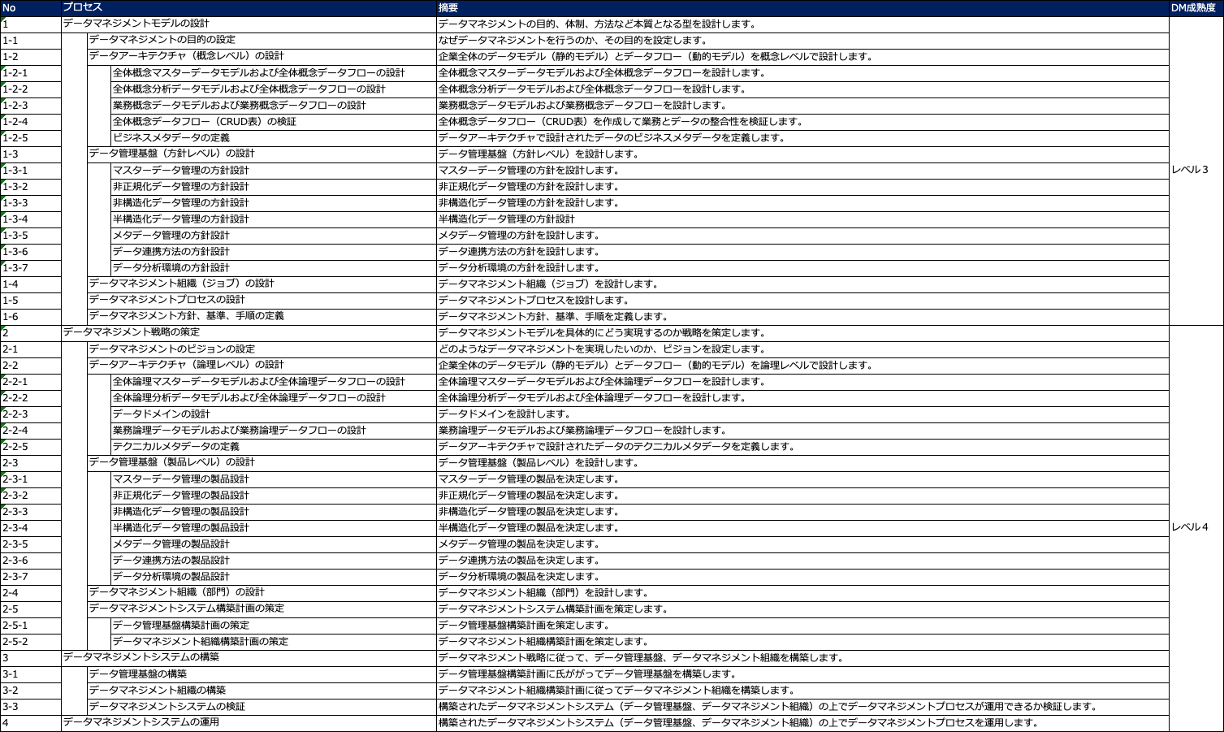
データマネジメントモデルを設計するとで、データマネジメント成熟度レベルが3になり、データマネジメント戦略を策定し、それに基づいて、データマネジメントシステムを構築、運用することでデータマネジメント成熟度レベルが4になります。
データマネジメント導入プロセスの詳細は次の記事を参照してください。
データマネジメントの導入方法